DPDK在DPVS中的应用及原理分析
本文最后更新于:November 12, 2020 pm
上一篇文章中我们已经介绍了DPVS的特点和部署方式,本文主要是用于介绍DPVS是如何实现前面所说的特点,或者说是如何提高性能的。
下图是爱奇艺的DPVS开发团队给出的DPVS在提高性能方面的操作,我们这里换一个角度,自底向上,从底层的CPU、内存、网卡来看这些操作是如何实现的。
(本文涉及到较多的计算机组织架构和操作系统原理的知识点,由于篇幅原因没办法一一详解,因此有一定的理解门槛,如果有看不懂的知识点可以在文章下面留言,有机会我会写一些文章详细介绍一下相关内容)

这里需要额外解释一下Share Nothing和Batching。
Shared nothing架构(Shared Nothing Architecture,SNA)这里的Share Nothing指的是一种设计模式而不是某种具体的技术,这种架构设计的思想是通过牺牲整体的横向扩展能力来提升纵向性能。作为一种分布式计算架构,它的每一个节点( node)都是独立、自给的,而且整个系统中没有单点竞争,没有资源的竞争就不需要加锁,也不需要上下文切换。
Batching在这里指的批处理,主要还是依靠DPDK的SIMD(Single Instruction Multiple Data,单指令流多数据流)编码思想以及处理器本身的SIMD指令集来实现。SIMD是一种采用一个控制器来控制多个处理器,同时对一组数据(又称“数据向量”)中的每一个分别执行相同的操作从而实现空间上的并行性的技术。在微处理器中,单指令流多数据流技术则是一个控制器控制多个平行的处理微元,例如Intel的MMX或SSE,以及AMD的3D Now!指令集。
1、From NIC drivers
PMD (Poll Mode Driver)
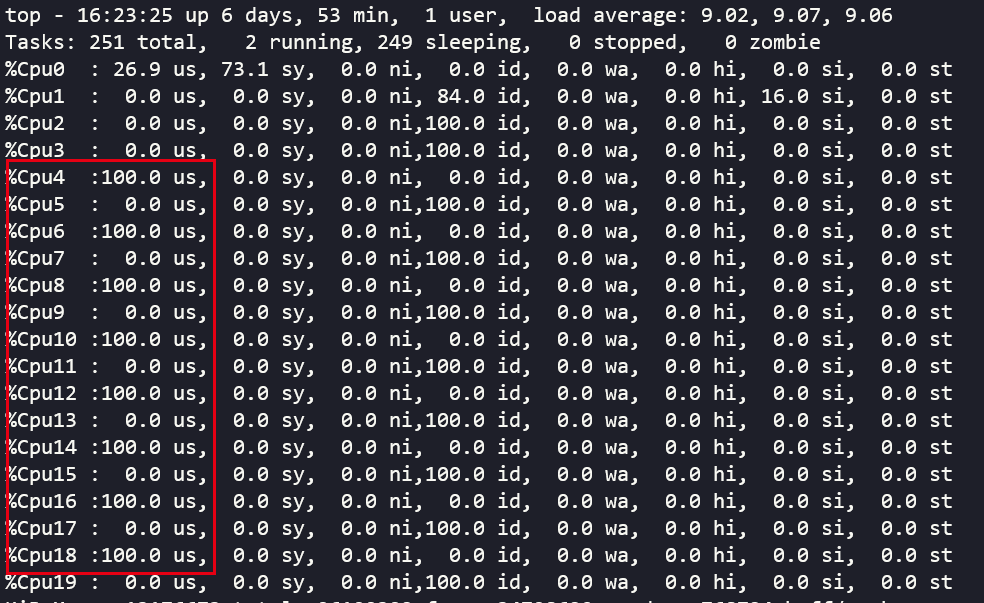
使用top命令查看系统资源占用,我们会发现在dpvs中对网卡收发队列进行了一一绑定的CPU核心占用率会一直维持在100%,并且是用户态的100%占用,并且无论是否有流量在所属的dpdk网卡上经过,都会一直维持在100%的状态。这是dpdk的一个特性,称之为**PMD(Poll Mode Driver)**。前面在安装dpdk的时候,我们需要使用dpdk给对应的网卡来安装特定的网卡驱动,比如我们这里用于测试使用的82599网卡使用的是UIO驱动,这些都是属于PMD驱动。目前DPDK支持1G、10G、40G以及半虚拟化的virtio网卡的PMD驱动。
对于运行着dpdk的机器,我们查看内核模块和对应的dpdk网卡驱动,可以发现uio模块和PMD驱动的踪迹,其中04:00.1是dpdk的网卡,而04:00.0则是普通状态下的网卡
1 | |
PMD驱动包含了各种API,并且提供了在用户态运行的BSD驱动,用于配置网卡和网卡的收发队列。此外,PWD驱动最大的优势就是无需任何中断操作就可以直接访问网卡队列中的RX/TX描述符(除了网卡的链接状态变化),借助这个优势,就可以绕过内核和同样运行在用户态的应用程序快速地进行数据传输。我们可以通过下图来对比传统的应用程序和网卡通信的方式以及使用PMD驱动后和网卡通信的方式。
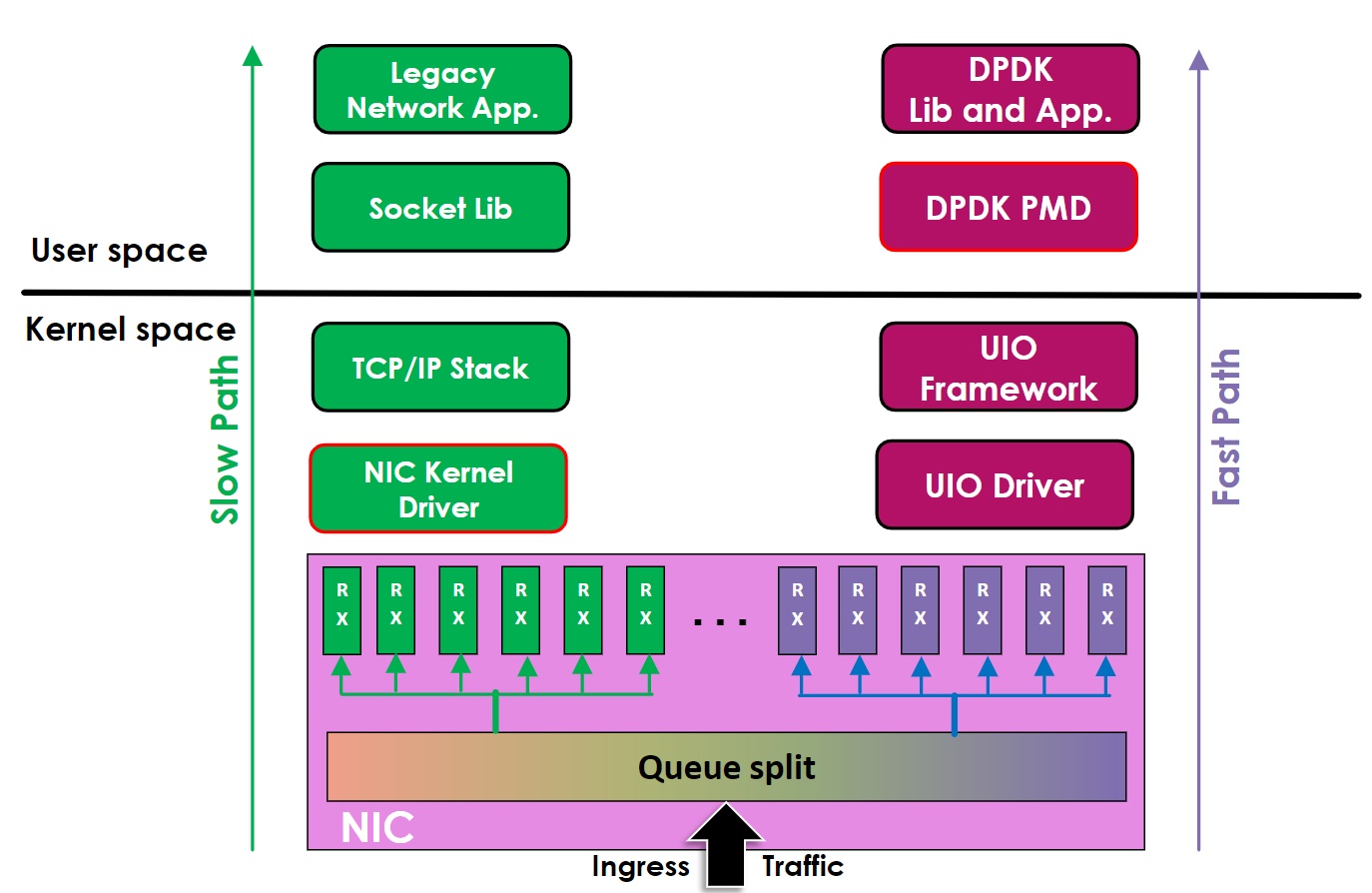
传统模式下,应用程序如nginx等运行在用户态(User Space),网卡(NIC)属于硬件设备,是归属于内核管理,网卡驱动运行在内核态中(Kernel Space)。那么当应用程序需要和网卡交换数据的时候,需要进行一轮用户态到内核态之间的切换,再经过内核中的TCP/IP协议栈,才能和网卡驱动通信,而网卡驱动和网卡之间的通信是通过硬件中断的方式来实现的,也就是传统模式下存在着用户态/内核态切换和两个非常耗时耗资源的操作。
DPDK的处理方式非常简单粗暴,首先将网卡驱动从内核态移动到用户态运行,这样应用程序和PMD网卡驱动之间进行数据交换就不需要进行内核态/用户态的切换,避免了上下文切换,且由于都是在用户态,不需要将数据拷贝到内核态,也实现了零拷贝zero copy,同时还绕过了内核中的TCP/IP网络栈,极大地缩短APP到Driver之间的传输时间。
当然这种绕过系统内核的做法最直接的代价就是驱动程序必须一直通过轮询poll的操作来保证能够及时接收到网卡的信息和数据,导致对应的cpu核心会一直处于100%的占用状态。同时这个时候网卡已经不再归于系统内核管理,常规的ip和ifconfig等命令已经没办法查看网卡的详细信息,需要使用dpip工具来对网卡进行管理。
这里就是dpvs宣称的内核旁路(kernel bypass)、轮询(polling)、零拷贝(zero copy)等特性的实现原理。
注意这种PMD驱动并不适用于一般的应用场景,因为需要有专门的CPU给PMD一直做轮询操作,对应的CPU就会一直占用100%,可能严重影响了其他任务的运行。
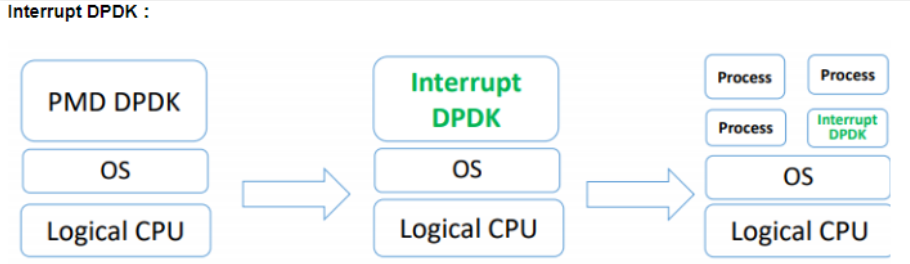
当网络处于空闲状态的时候,CPU占用100%的问题会带来额外的不必要的功耗,因此dpdk还推出了一个interrupt dpdk模式,即当网卡中没有数据包处理的时候进入类似睡眠模式的状态,然后改为传统的中断方式通知,这个时候被100%占用的核心利用率就会降低,可以和其他的进程共享,但是DPDK仍然拥有高优先级,而当有数据包进来的时候还是可以优先处理。
2、From CPU
NUMA Awareness
1.从系统架构来看,目前的商用服务器大体可以分为三类
- 对称多处理器结构(SMP:Symmetric Multi-Processor)
- 非一致存储访问结构(NUMA:Non-Uniform Memory Access)
- 海量并行处理结构(MPP:Massive Parallel Processing)
2.共享存储型多处理机有两种模型
- 均匀存储器存取(Uniform Memory Access,简称UMA)模型
- 非均匀存储器存取(Nonuniform Memory Access,简称NUMA)模型
前面我们在安装dpvs的时候,特别需要注意的就是需要在BIOS中开启NUMA,这里主要涉及到的就是对于多路服务器(往往多颗CPU在一块主板上)的内存调度优化问题。以我们的测试服务器为例来进行举例说明:这台普通的R630服务器一共有两颗CPU,128G内存,其中内存是均匀分布在两颗CPU上的,即每颗CPU的内存总线都对应连接着64G的内存。那么NUMA打开和关闭的区别在哪里呢?
对于关闭NUMA的机器,在Linux系统中查看的时候只有一个NUMA节点,系统会以为只有一颗CPU,那么这128G内存就都是这一颗CPU的,这样的好处是在应用程序可以通过操作系统跨NUMA节点调度另外一颗CPU的内存,虽然一颗CPU只有64G内存的,但是在这个CPU上面运行的程序可以调用128G的内存,实在不够了再调用SWAP内存。对于一般的应用程序来说,即使是使用了另外一颗CPU的内存会带来较高的延时,但是性能也远比swap内存强多了。
关于是否开启处理器的超线程技术,主要分析如下:
超线程(Hyper-Threading)在一个处理器中提供两个逻辑执行线程,逻辑线程共享流水线、执行单元和缓存。该技术的本质是复用单处理器中的超标量流水线的多路执行单元,降低多路执行单元中因指令依赖造成的执行单元闲置。对于每个逻辑线程,拥有完整独立的寄存器集合和本地中断逻辑,从软件的角度,与单线程物理核并没有差异。例如,8核心的处理器使用超线程技术之后,可以得到16个逻辑线程。采用超线程,在单核上可以同时进行多线程处理,使整体性能得到一定程度提升。但由于其毕竟是共享执行单元的,对IPC(每周期执行指令数)越高的应用,带来的帮助越有限。DPDK是一种I/O集中的负载,对于这类负载,IPC相对不是特别高,所以超线程技术会有一定程度的帮助。
对于打开NUMA的机器,在本身的CPU内存用尽的情况下,不会去跨NUMA节点调度另外一颗CPU的内存,而是直接调用swap内存。对于DPDK程序来说,这样的好处就是尽可能地降低内存的延迟,提高性能表现。由于DPDK广泛的使用了大页内存(HugePage),可以有效地控制内存的超用问题,不会涉及到swap内存的调用。
RSS(Receive Side Scaling)
同样的除了内存之外,问题还存在于网卡设备上。一般来说网卡设备是通过PCIe总线和CPU连接,不同CPU之间跨NUMA节点调用PCIe设备带来的性能损耗实际上并没有内存那么大,因为PCIe总线并没有内存总线距离CPU那么“近”,而且两者的带宽也不是在一个数量级上。
还是前面用到的那张网卡,我们使用lspci命令查看pci设备信息的时候我们可以看到对应的NIC设备的信息(截取部分):
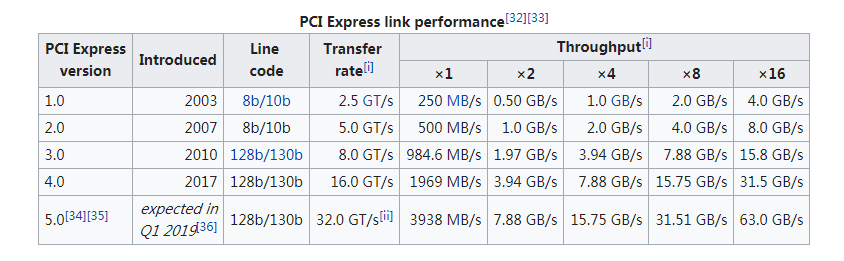
这里可以看到5GT/s对应的是PCIe2.0,x8则表示带宽,这里使用的是一个PCIe2.0x8的双口万兆网卡82599ES
GT/s是PCIe设备用来表示带宽的单位,具体对应速度转换可以查看下面的这个表格
NUMA node表示这块PCIe网卡插在的插槽是哪一颗CPU对应的PCIe总线
1 | |
RSS(Receive Side Scaling)功能的实现其实和网卡以及CPU都有关系,但是这里放到CPU的部分来分析,主要是需要前面提及的技术作为支撑。关于RSS的一些说明我们可以参考Linux内核的官网文档,此外微软的官方文档也有不错的图文解释。
RSS,接收方缩放(直译起来略显晦涩生硬),使用搜索引擎的时候建议搜全名Receive Side Scaling,搜缩写RSS容易搜到
Really Simple Syndication,中文译作简易信息聚合,也称聚合内容,是一种消息来源格式规范,用以聚合经常发布更新资料的网站,例如博客文章、新闻、音频或视频的网摘。
现在的网卡基本都支持多队列(multi-queue)技术,而队列是分为收和发两种的。在接收数据包的时候,网卡可以把数据包发往不同的消息队列(一般通过哈希算法),不同的消息队列对应不同的CPU,这样就可以做到并行处理数据。典型的RSS配置是:如果设备支持足够的队列,则每个CPU有一个接收队列(一般多网卡机器上网卡的总队列数会超过CPU核心数,因此CPU核心数和网卡队列数一一对应即可),否则,每个内存域(如一个NUMA节点)至少有一个接收队列。
基于这些特性,DPVS可以在配置中设定worker进程、CPU核心和网卡收发队列的一一绑定,最好的情况下就是全部都是在一颗物理CPU上,这样带来的性能提升最明显。
这是DPVS宣传的NUMA Awareness和RX steering&CPU的技术原理。
3、From memory
Huge page大页内存
DPDK广泛使用了大页内存(2M或者1G)机制(对于DPVS来说,主要使用的是2MB的大页内存),以Linux系统为例,1G的大页一般不能在系统加载后动态分配,所以一般会在内核加载的时候设置好需要用到的大页。例如,增加内核启动参数default_hugepagesz=1G hugepagesz=1G hugepages=8来配置好8个1G的大页。在Linux系统上,可以通过命令cat /proc/meminfo来查看系统加载后的内存状况和大页内存的分配状况。
1 | |
注意上面的AnonHugePages和我们这里要讲的Hugepages不是一类东西,建议忽略。同时Hugepages不会备注大小,上面的Hugepagesize表明使用的是2MB的大页内存,而HugePages_Total表明有16384个这么大的大页内存,所以这里一共是32GB的大页内存。
在继续后面的内容之前我们需要了解一下TLB是什么。
首先,我们知道MMU(Memory Management Unit)的作用是把虚拟内存地址转换成物理内存地址。虚拟地址和物理地址的映射关系存储在页表中,而现在页表又是分级的。64位系统一般都是3~5级。常见的配置是4级页表,就以4级页表为例说明。分别是PGD、PUD、PMD、PTE四级页表。
在硬件上会有一个叫做页表基地址寄存器,它存储PGD页表的首地址。MMU就是根据页表基地址寄存器从PGD页表一路查到PTE,最终找到物理地址(PTE页表中存储物理地址)。四级页表查找过程需要四次内存访问。延时可想而知,非常影响性能。(下图来自知乎)

TLB的本质其实就是一块高速缓存。数据cache缓存地址(虚拟地址或者物理地址)和数据。TLB缓存虚拟地址和其映射的物理地址。TLB根据虚拟地址查找cache,它没得选,只能根据虚拟地址查找。所以TLB是一个虚拟高速缓存。硬件存在TLB后,虚拟地址到物理地址的转换过程发生了变化。虚拟地址首先发往TLB确认是否命中cache,如果cache hit直接可以得到物理地址。否则,一级一级查找页表获取物理地址。并将虚拟地址和物理地址的映射关系缓存到TLB中。
默认下Linux系统的内存采用4KB为一页,页越小且内存越大则页表的开销越大,页表的内存占用也越大。CPU使用的TLB(Translation Lookaside Buffer)制作成本很高,所以一般大小并不大,因此一般就只能存放几百到上千个页表项。如果进程要使用64G内存,则64G/4KB=16000000(一千六百万)页,每页在页表项中占用16000000*4B=62MB。如果用HugePage采用2MB作为一页,只需64G/2MB=2000,数量不在同个级别。
而DPDK采用HugePage,在×86-64下支持2MB、1GB的页大小,几何级的降低了页表项的大小,从而减少TLB-Miss,并提供了内存池(Mempool)、MBuf、无锁环(Ring)、Bitmap等基础库。
而且对于普通应用程序而言,根本不会调用到大页内存,且大页内存分配之后立刻就会在系统的可用内存中划去,不管dpdk程序是否使用,都不会被其他程序占用,在只运行了dpdk程序的机器上,划分出的大页内存区域就是该dpdk程序独享的VIP区。
这里就是DPVS宣传的mempool和HugePage特性的实现原理。
4、总结
稍加深入分析之后我们不难发现DPVS的高性能实现基本都是依靠特定硬件和DPDK来实现的,那么DPVS的优势在哪里呢?
实际上DPDK作为一套开发套件,本身并不是特别的完善,由于它的PMD驱动绕过了内核的网络栈,因此想要实现DPDK+LVS的核心难度在于如何在用户态实现一套轻量级的网络协议栈(L4LB不需要完整的网络栈),这也是DPVS的最核心难点之一。