在k8s中的controller简介
本文最后更新于:July 22, 2019 pm
运行容器化应用是Kubernetes最重要的核心功能。为满足不同的业务需要,Kubernetes提供了多种Controller,主要包括Deployment、DaemonSet、Job、CronJob等。
1、创建资源的两种方式
创建资源主要有通过命令行配置参数和通过配置文件这两种方式。
通过命令行主要是使用
kubectl命令来进行创建,主要可能用到的是kubectl run和kubectl create,具体的用法我们可以在命令后面加上–-help参数来查看帮助文档。这种方式的好处就是简单快捷,部署的速度比较快,但是遇到要求比较复杂多样的资源部署,后面就要附带一大串参数,容易出错,所以这种方式一般来说比较适用于小规模的简单资源部署或者是上线前的简单测试
通过配置文件则主要是
json格式或yaml格式的文件,好处是可以详细配置各种参数,保留的配置文件还可以用到其他的集群上进行大规模的部署操作,缺点就是部署比较麻烦,并且需要一定的门槛(要求对json或yaml有一定的了解)配置文件主要是通过
kubectl apply -f和kubectl create -f来进行配置。
2、Deployment
2.1 cli部署
我们先使用命令行(cli)创建一个deployment,名字(NAME)是nginx-clideployment,使用的镜像(image)版本为1.17,创建的副本(replicas)数量为3。
1 | |
我们查看一下部署是否成功:
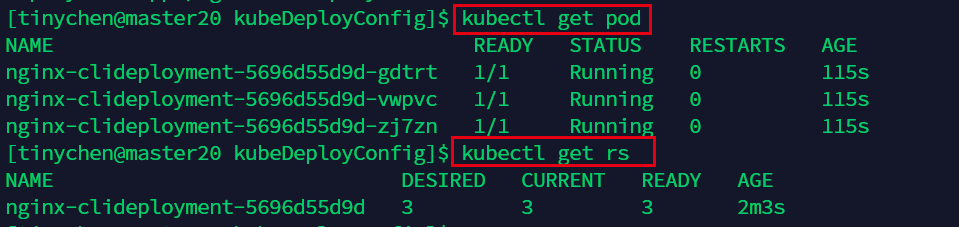
这里的kubectl get rs中的rs其实就是ReplicaSet(RS)
我们还可以发现ReplicaSet的命名就是在我们指定的NAME后面加上了一串哈希数值。
<the name of the Deployment>-<hash value of the pod template>.
想要查看更详细的pod情况,我们可以这样:
1 | |

这里我们可以发现三个pod被k8s自动的分配到了三个节点上而实现集群中的负载均衡(LB),而这里的IP是创建pod的时候进行随机分配的,我们并不能预知。
如果想要查看某一个pod部署之后的情况,我们可以这样:
1 | |
如果我们只是输入nginx-clideployment的话就会把所有相关的nginx-clideployment都列出来。
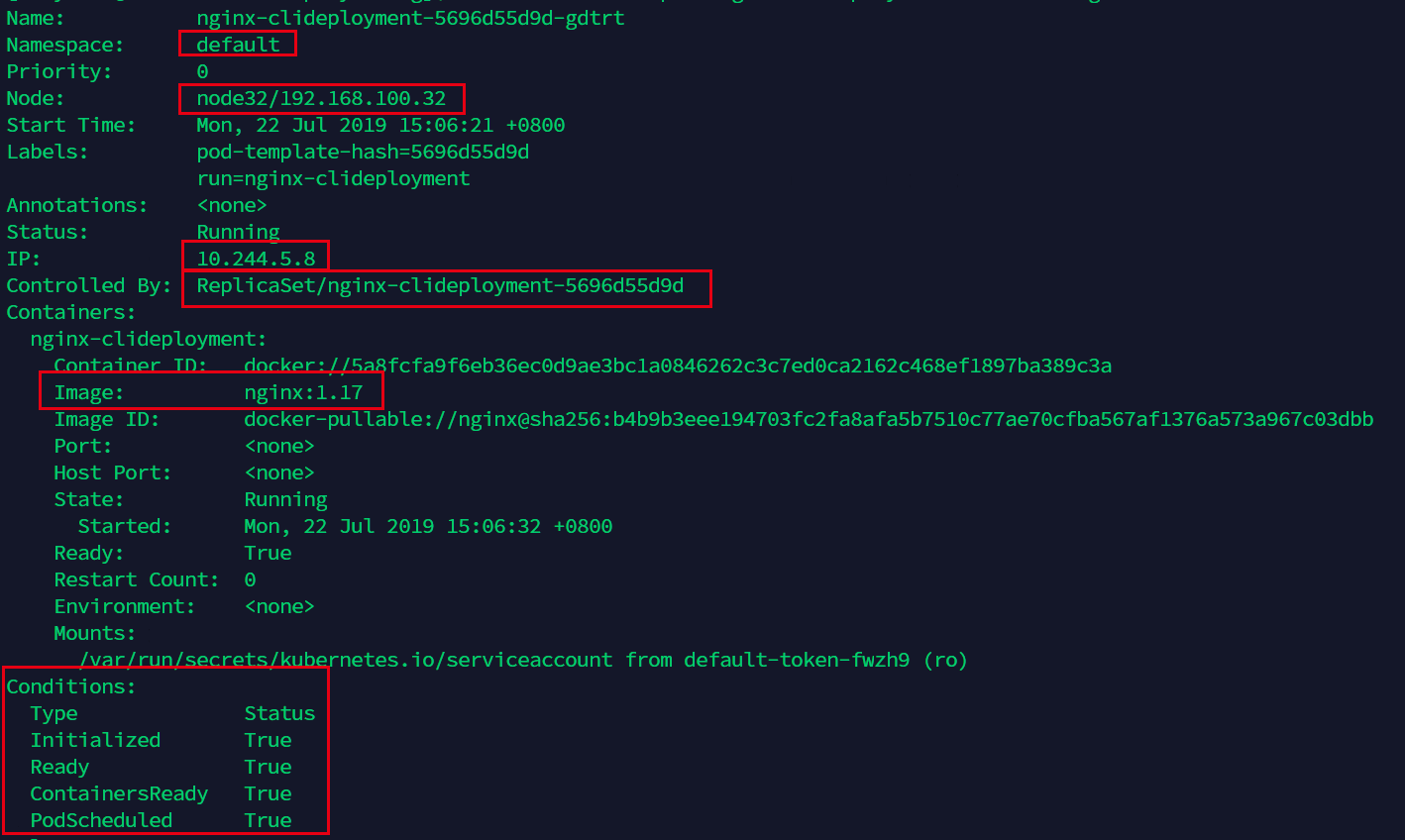
这里的信息很多,我们可以看到namespace是使用的默认default(一般都是default,除非是数十人以上在同时使用这个集群,否则一般不建议新建namespace来区分pod,大多数情况下使用label即可区分各类pod。)
Controlled By: 则说明了这个deployment是由ReplicaSet控制的。
Conditions:则表明了当前的pod状况
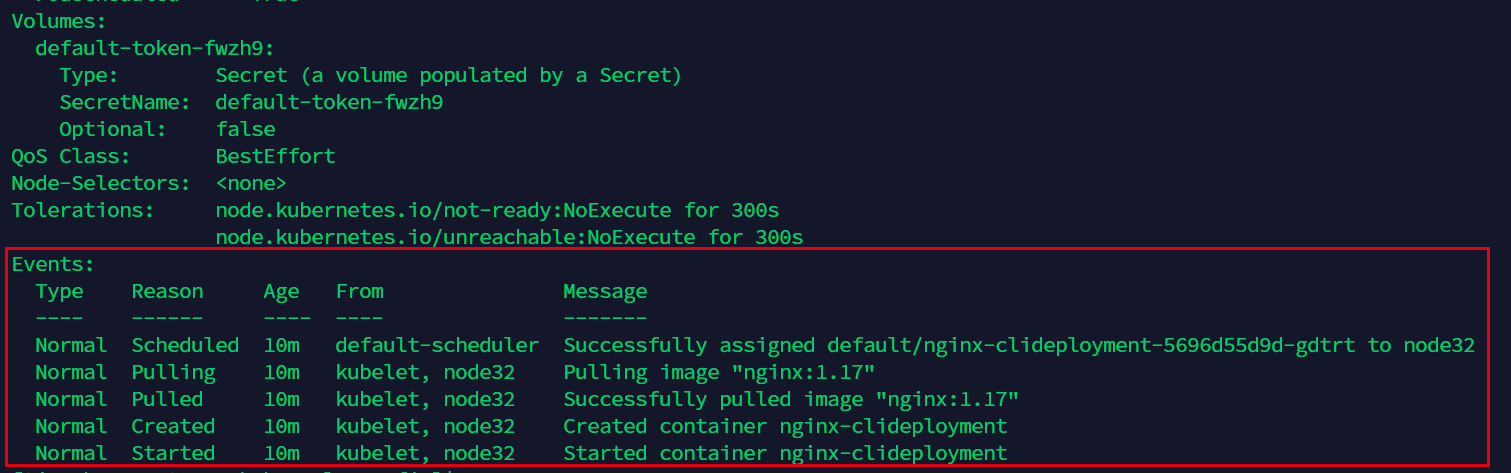
Volumes称之为卷,这个概念我们暂时还没有接触到,等到我们的宿主机需要与容器内的服务进行数据交互的时候再进行了解。
Events则相当于log,记录了pod运行的所有情况,如果遇到了运行不正常的情况,我们也可以查看这里来了解详情。
2.2 yaml配置文件部署
接下来我们尝试使用yaml文件来进行部署。我们新建一个文件,命名为nginx-yamldeployment.yml
1 | |
- apiVersion是当前配置格式的版本。
- kind是要创建的资源类型,这里是Deployment。
- metadata是该资源的元数据,name是必需的元数据项。
- spec部分是该Deployment的规格说明。
- replicas 指明副本数量,默认为1。
- template 定义Pod的模板,这是配置文件的重要部分。
- metadata定义Pod的元数据,至少要定义一个label。label的key和value可以任意指定。
- spec 描述Pod的规格,此部分定义Pod中每一个容器的属性,name和image是必需的。
接下来我们使用kubectl apply指令进行部署。
1 | |


我们可以看到这里是已经运行正常了,那么如果我们想要修改这个deployment的属性,比如说副本数量从5改为6,那么我们可以直接编辑刚刚的nginx-yamldeployment.yml文件,然后再执行kubectl apply -f nginx-yamldeployment.yml,但是如果文件找不到了,我们可以使用另外的方法:
1 | |
这样子我们就能直接编辑这个deployment的yaml配置文件,编辑的操作方式和vim相同,修改完成后会自动生效。
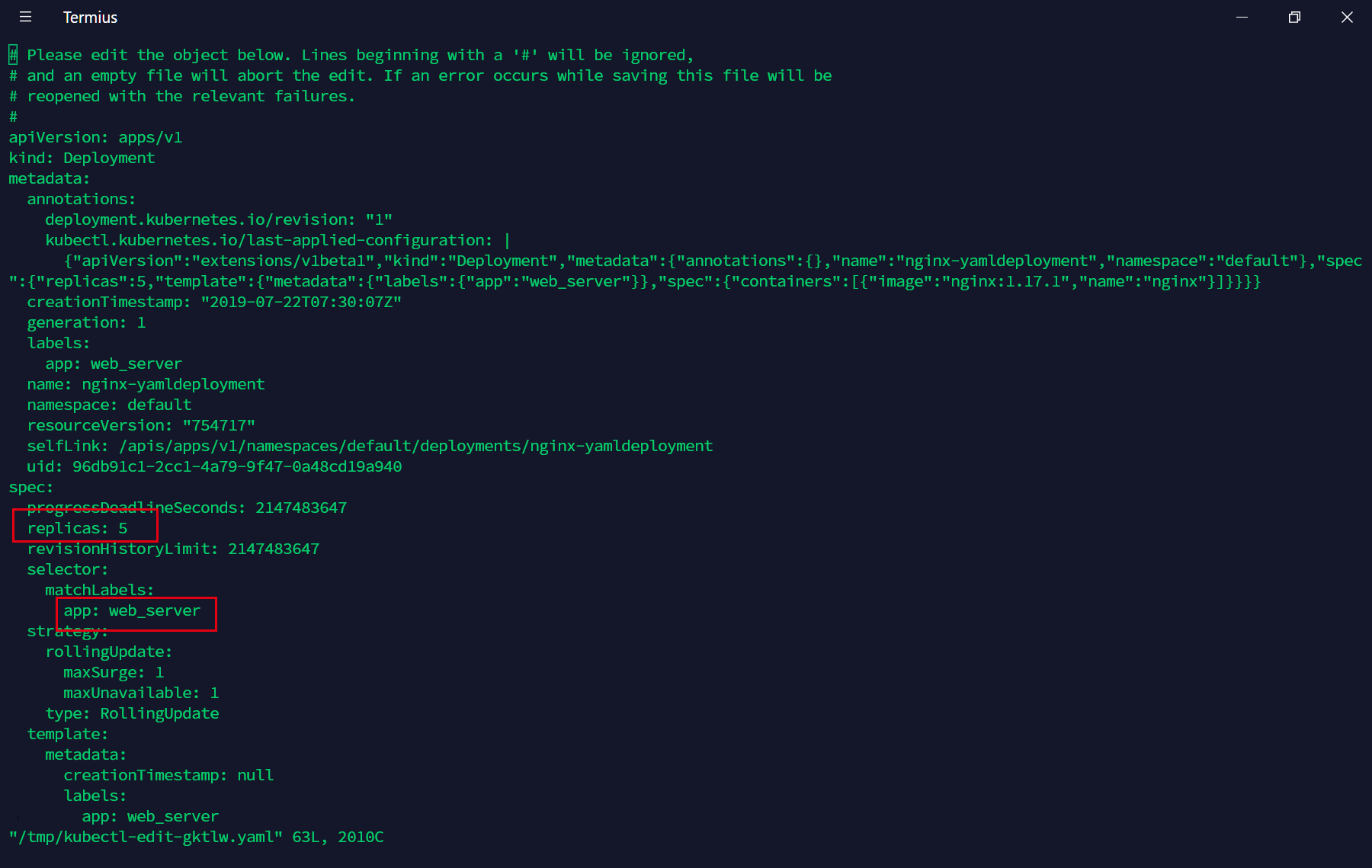
我们修改保存退出后,可以看到这里已经生效了。

对于使用命令行创建的deployment,我们可以使用命令行来进行修改,也可以直接
kubectl edit来编辑对应的yaml配置文件。
3、DaemonSet
我们先来看一下官网对DaemonSet的解释:
DaemonSet 确保全部(或者某些)节点上运行一个 Pod 的副本。当有节点加入集群时,也会为他们新增一个 Pod 。 当有节点从集群移除时,这些 Pod 也会被回收。删除 DaemonSet 将会删除它创建的所有 Pod。
使用 DaemonSet 的一些典型用法:
- 运行集群存储 daemon,例如在每个节点上运行
glusterd、ceph。 - 在每个节点上运行日志收集 daemon,例如
fluentd、logstash。 - 在每个节点上运行监控 daemon,例如
Prometheus Node Exporter、collectd、Datadog代理、New Relic代理,或Ganglia gmond。
一个简单的用法是在所有的节点上都启动一个 DaemonSet,将被作为每种类型的 daemon 使用。 一个稍微复杂的用法是单独对每种 daemon 类型使用多个 DaemonSet,但具有不同的标志,和/或对不同硬件类型具有不同的内存、CPU要求。
实际上,k8s本身的一些系统组件服务就是以DaemonSet的形式运行在各个节点上的。

4、Job
4.1 部署job
- Job创建一个或多个Pod并确保指定数量的Pod成功终止。当pod成功完成后,Job会跟踪成功的完成情况。达到指定数量的成功完成时,Job完成。
- 删除Job将清理它创建的Pod。
- 一个简单的例子是创建一个Job对象,以便可靠地运行一个Pod并成功完成指定任务。如果第一个Pod失败或被删除(例如由于节点硬件故障或节点重启),Job对象将启动一个新的Pod。
- 我们还可以使用Job并行运行多个Pod。
直接照搬官网的解释可能会有些难以理解,我们来运行一个例子就能很好的说明情况了。
我们先新建一个job的配置文件,命名为pijob.yml,这个任务是将pi计算到小数点后两千位,然后再打印出来。我们运行一下看看。
1 | |

我们查看它的详细情况
1 | |
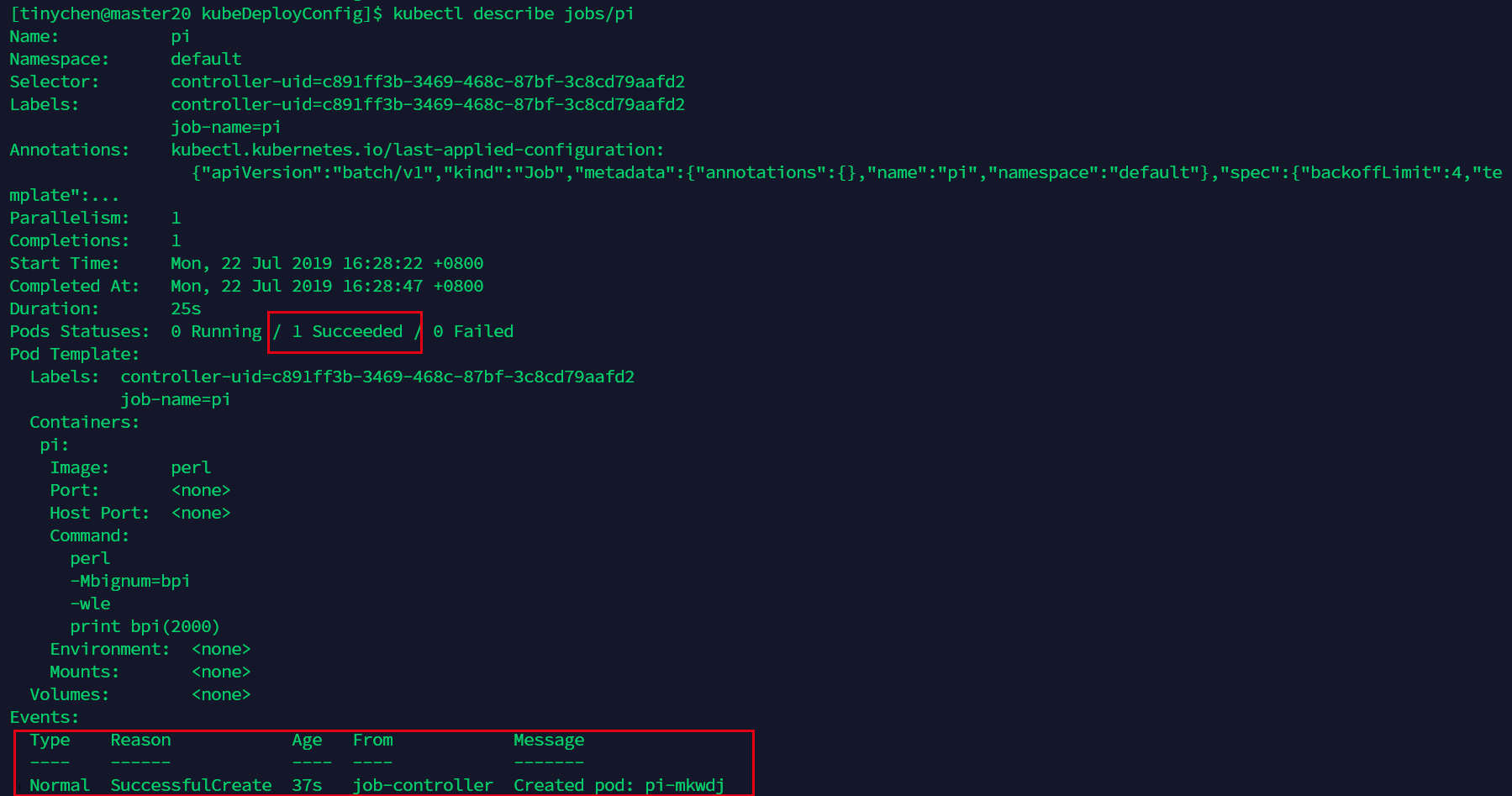
这里可以看到,运行了37s后成功计算出结果。
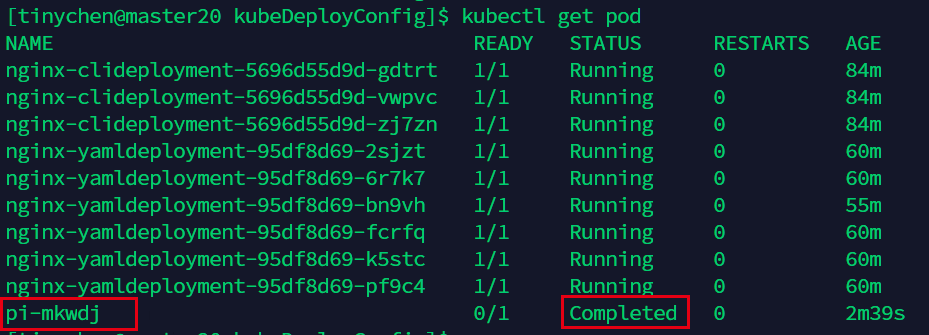
查看pod也可以看到它的状态是Completed,说明已经完成了。
1 | |
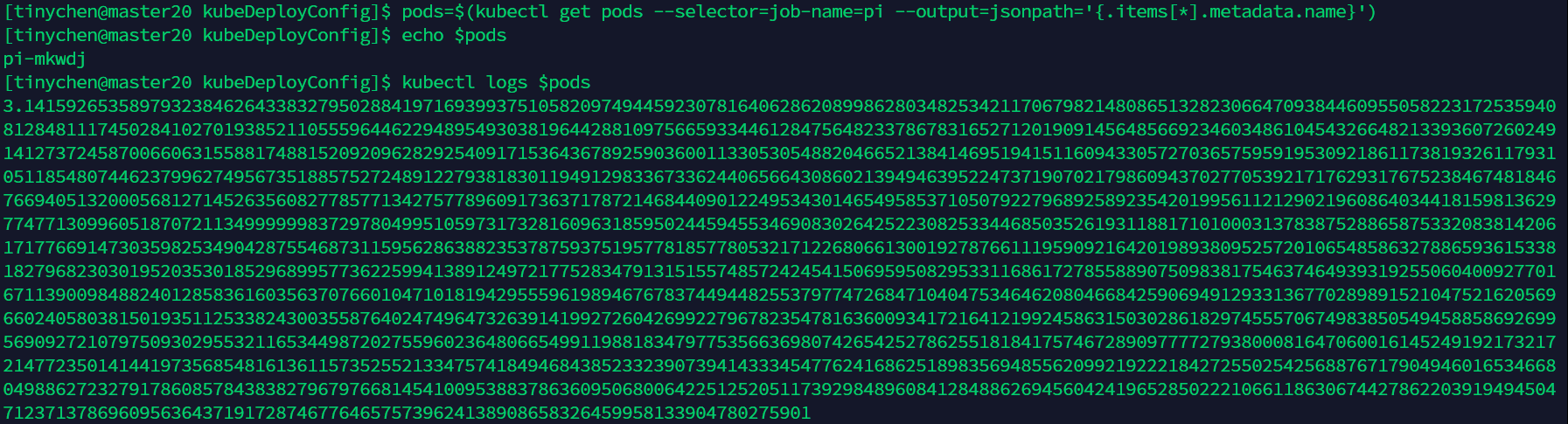
4.2 job运行错误
我们现在来看一下运行失败的情况,我们把command里面的路径改错,使得它无法正常运行。
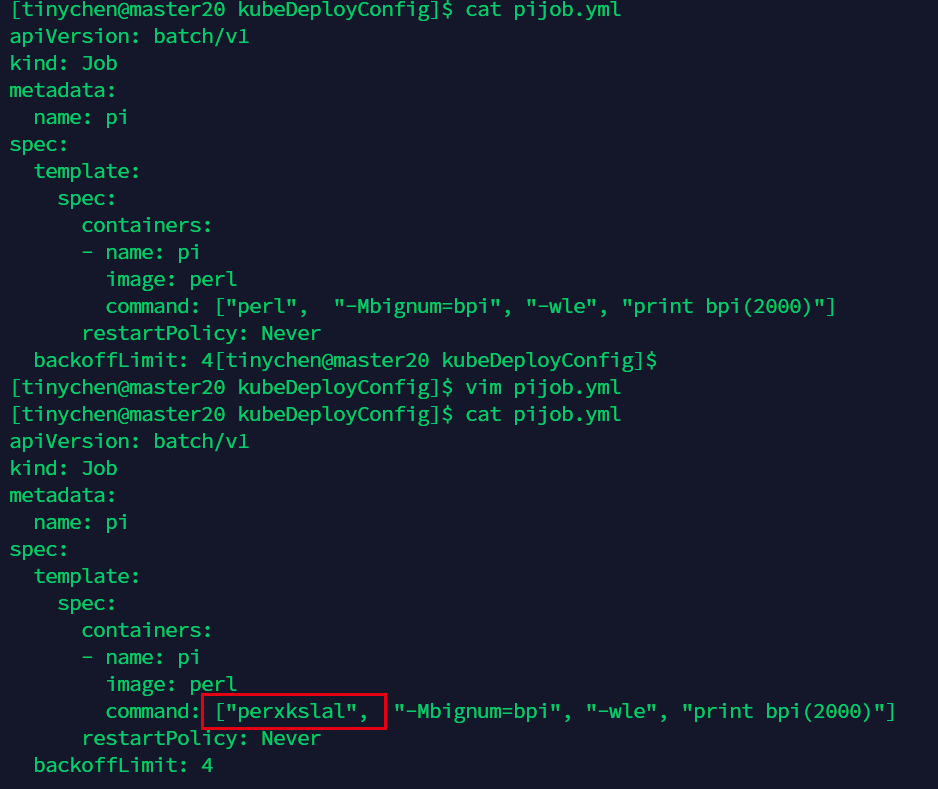
注意这里的restartPolicy: Never意味着pod运行失败了也不会重启。但是这个时候job会检测到运行失败,然后再新建一个pod来执行这个任务。
backoffLimit: 4意味着最多只会新建4个pod,避免一直失败一直新建从而耗尽系统资源。
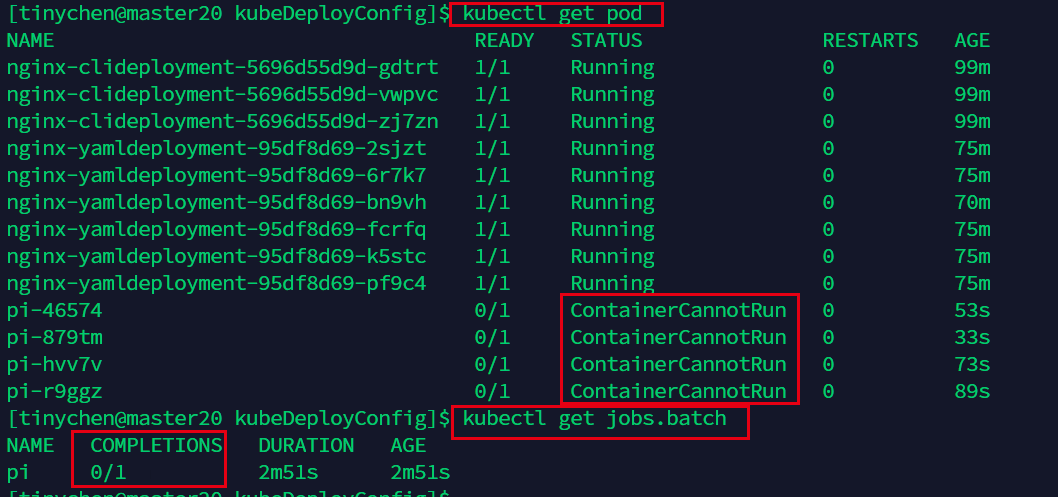
我们查看event可以看到,确实是由于路径修改错误而导致无法正常运行。

接下来我们把restartPolicy: 改为 OnFailure
这时候我们可以看到并没有启动多个pod,二是对发生错误的pod进行重启操作。
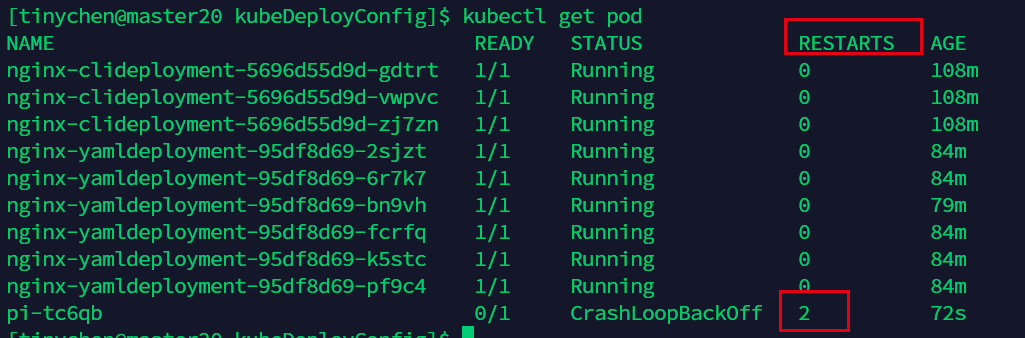
4.3 job并行化
在多线程早已普及的今天,很多任务我们都可以使用并行化来进行加速运行,这里也不例外。
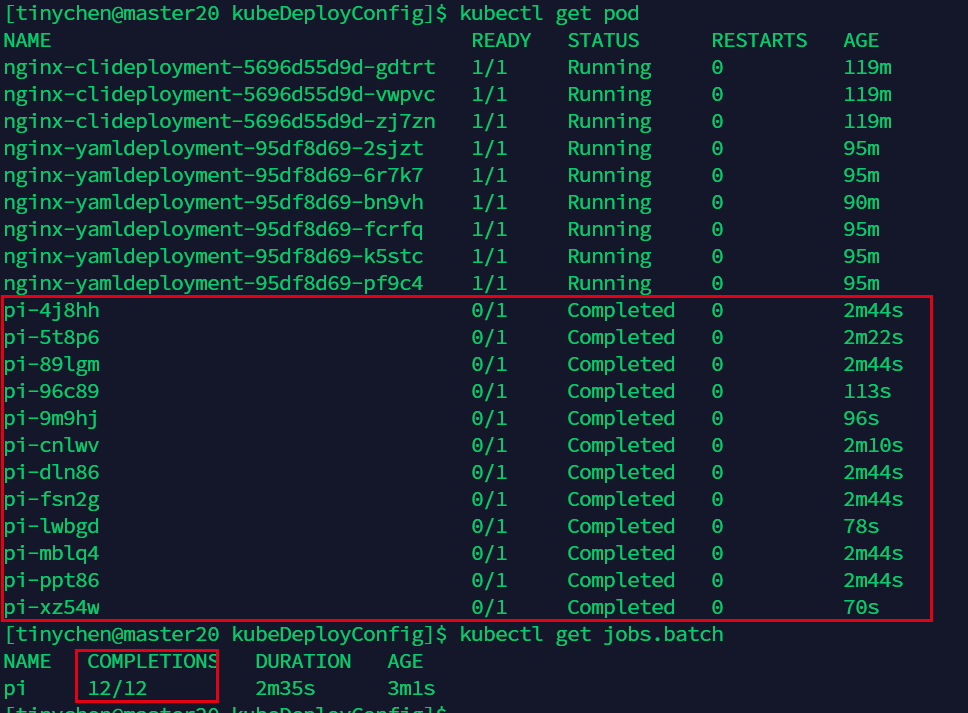
我们在配置文件中的spec中加入 completions: 和parallelism: 。
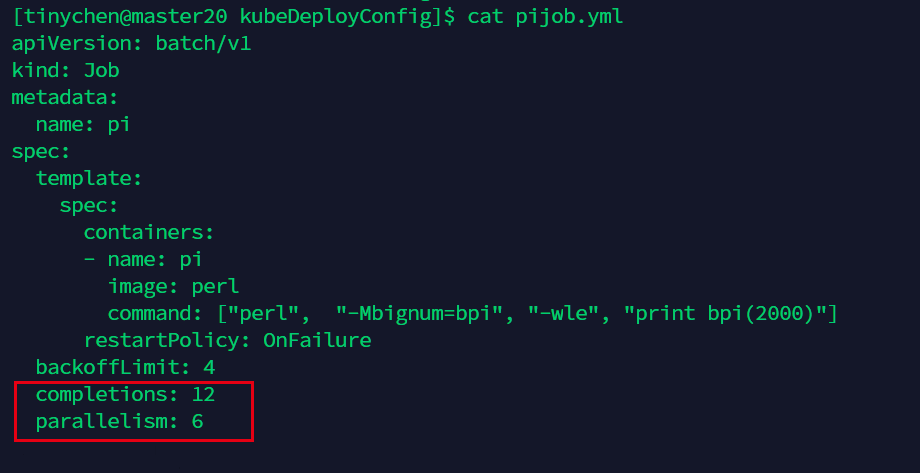
图中表示需要运行12个,每次并行运行6个。
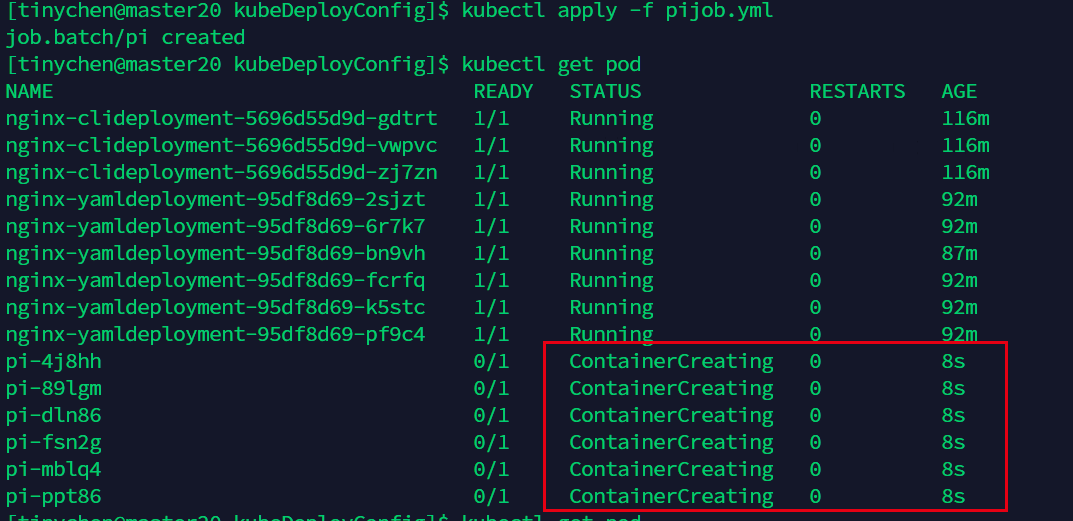
从图中我们可以看到确实是每次运行6个(运行时间相同说明同时开始运行)。
等待一段时候之后,我们再次查看而已看到任务已经顺利完成了。
5、CronJob
熟悉linux的同学一定不会对cron感到陌生,因为cron就是用来管理linux中的定时任务的工具,所以CronJob我们可以理解为定时版的Job,其定时任务的编写格式也和Cron相似。关于Cron可以点击这里查看小七之前的博客。
需要注意的是,CronJob的时间以启动该CronJob任务的Master节点的时间为准。
Cronjob只负责创建与其计划相匹配的Job,而Job则负责管理它所代表的Pod。也就是说,CronJob只负责创建Job,具体的管理操作还是由Job来负责。
这里是CronJob的官方文档。
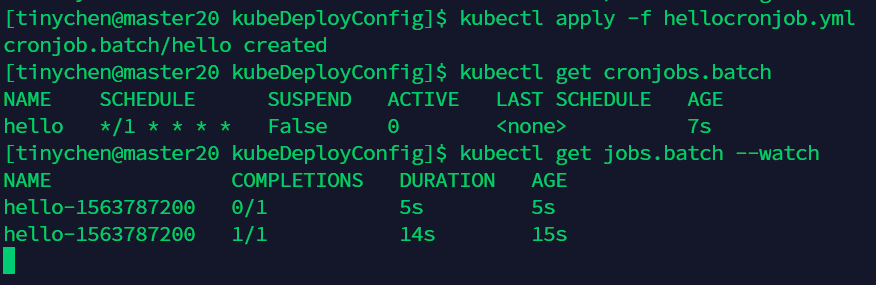
我们新建一个hellocronjob.yml来查看一下它的工作情况。
1 | |
这个定时任务的操作就是每分钟输出一次时间和Hello from the Kubernetes cluster。
1 | |
我们随便查看其中的一个log可以看到输出的结果:
