编译原理复习提纲
本文最后更新于:January 17, 2019 pm
《编译原理》复习提纲,啥也别说了,大家考试好运(ง •_•)ง
编译过程
编译程序的基本任务是将源语言程序翻译成等价的目标语言程序。
一般的,将编译过程划分成词法分析、语法分析、语义分析、中间代码生成、代码优化和目标代码生成6个阶段。
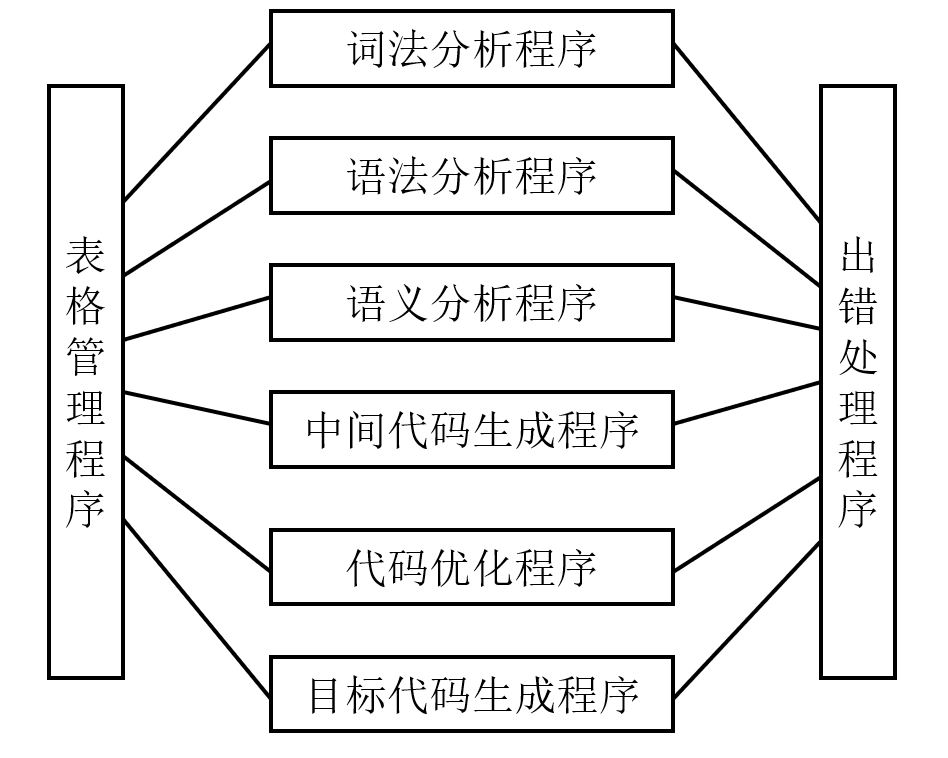
词法分析
词法分析的任务是从左到右一个字符一个字符地读入源程序,对构成源程序的字符流进行扫描和分解,从而识别出一个个单词(一些场合下也称单词符号或符号)。
这里所谓的单词是指逻辑上紧密相连的一组字符,这些字符具有集体含义。
语法分析
语法分析的任务是再词法分析的基础上将单词序列分解成各类语法短语。
这种语法短语也称为语法单位,可表示成语法树,如图所示。
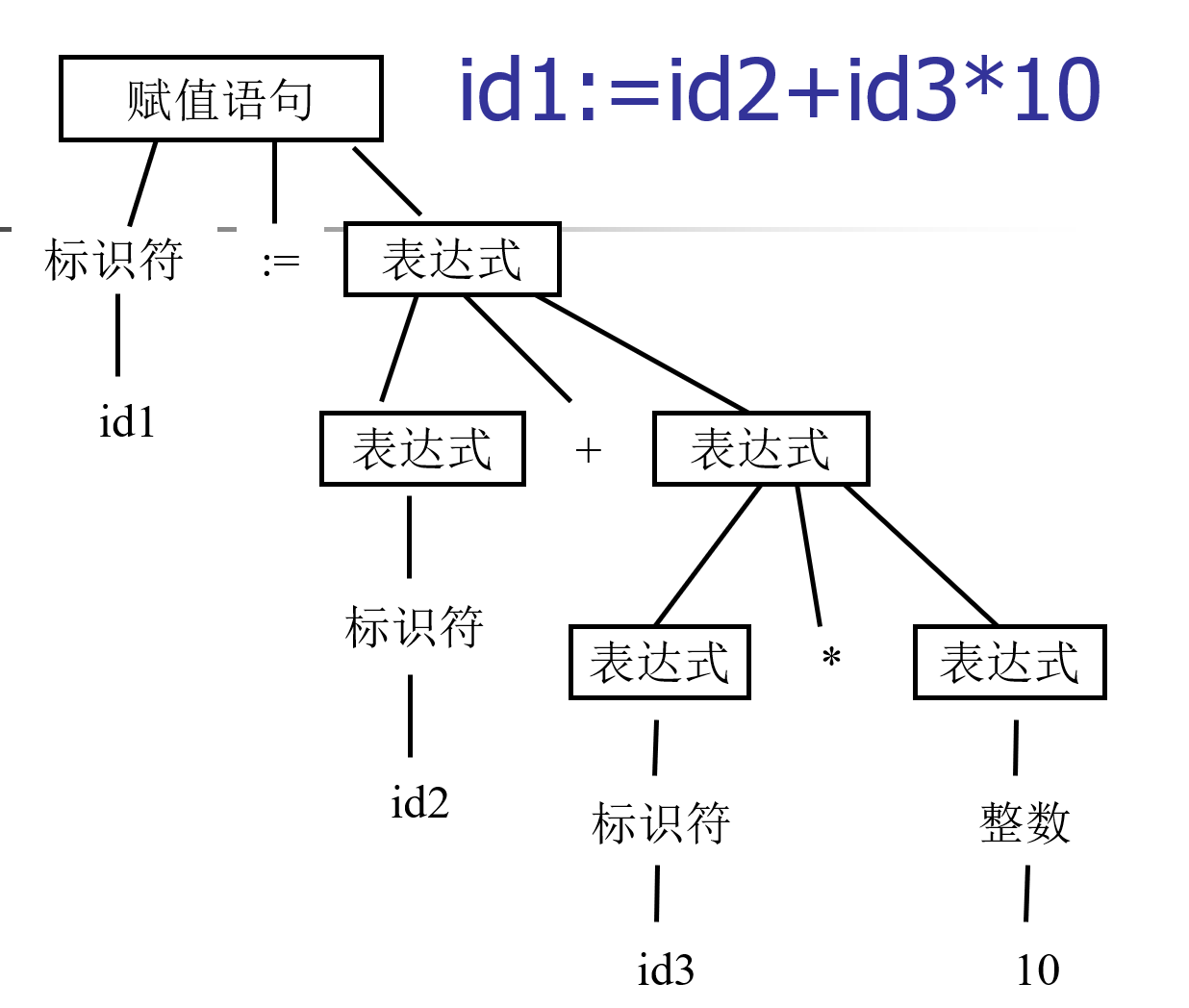
语法分析所依据的是语言的语法规则,即描述程序结构的规则。通过语法分析确定整个输入串是否构成一个语法上正确的程序。
词法分析和语法分析本质上都是对源程序的结构进行分析。但词法分析的任务仅对源程序进行线性扫描即可完成,比如识别标识符,因为标识符的结构是字母打头的字母和数字串,这只要顺序扫描输入流,遇到既不是字母又不是数字的字符时,将前面所发现的所有字母和数字组合在一起构成标识符单词即可。但这种线性扫描不能用于识别递归定义的语法成分,比如不能用此办法去匹配表达式中的括号。
语义分析
- 语义分析是审查源程序有无语义错误,为代码生成阶段收集类型信息。
例如,语义分析的一个工作是进行类型审查,审查每个算符是否具有语言规范允许的运算对象,当不符合语言规范时,编译程序应报告错误。
中间代码生成
在进行了上述的语法分析和语义分析阶段的工作之后,有的编译程序将源程序变成一种内部表示形式,这种表现形式叫做中间语言或中间代码。
所谓“中间代码”是一种结构简单、含义明确的记号系统,这种记号系统可以设计为多种多样的形式,重要的设计原则为两点:一是容易生成;二是容易将它翻译成目标代码。
很多编译程序采用了一种近似“三地址指令”的“四元式”中间代码,这种四元式的形式为
(运算符,运算对象1,运算对象2,结果)
id1:= id2 + id3 * 10
(1) (* id3 10 t1)
(2) (+ id2 t1 t2)
(3) (:= t2 - id1)
代码优化
对前一阶段产生的中间代码进行变换或进行改造,目的是使生成的目标代码更为高效,即省时间和省空间。
id1:= id2 + id3 * 10
(1) (* id3 10 t1)
(2) (+ id2 t1 id1)
目标代码生成
把中间代码变换成特定机器上的一个绝对指令代码或可重定位的指令代码或汇编指令代码。
(1) (* id3 10 t1)
(2) (+ id2 t1 id1)
mov id3,R2
mul 10, R2
mov id2,R1
add R2,R1
mov R1,id1
上述编译过程的阶段划分是一个典型处理模式,事实上并非所有的编译程序都分成这几个阶段,有些编译程序并不需要生成中间代码,有些编译程序不进行优化,即优化阶段可省去,有些最简单的编译程序在语法分析的同时产生目标指令代码,如PL/0语言编译程序。不过多数实用的编译程序都包含上述几个阶段的工作过程。
编译程序其他要点
符号表
记录源程序中使用的名字
收集每个名字的各种属性信息
类型、作用域、分配存储信息
出错处理
检查错误、报告出错信息、排错、恢复编译工作。
编译阶段的划分
前端和后端
编译的前端:与源语言有关但与目标机无关的那些部分组成
编译的后端:与目标机有关的那些部分组成
- 一个前端+多个后端:多平台编译器 例 Java
- 多个前端+一个后端:多语言编译器 例 .NET
- 遍(趟):从头到尾扫描源程序一次称为一遍
解释过程(解释程序)
这里介绍另一种语言处理程序,它不需要在运行前先把源程序翻译成目标代码,也可以实现在某台机器上运行程序并生成结果。
解释程序接受某个语言的程序并立即运行这个源程序。它的工作模式是一个个的获取、分析并执行源程序语句,一旦第一个语句分析结束,源程序便开始运行并生成结果,它特别适合程序员以交互工作方式工作的情况,即希望在获取下一个语句之前了解每个语句的执行结果,允许执行时修改程序。
著名的解释程序有Basic语言解释程序 ,Lisp语言解释程序,UNIX命令语言解释程序(shell),数据库查询语言SQL 解释程序以及bytecode解释程序。
编译程序和解释程序的对比
概念
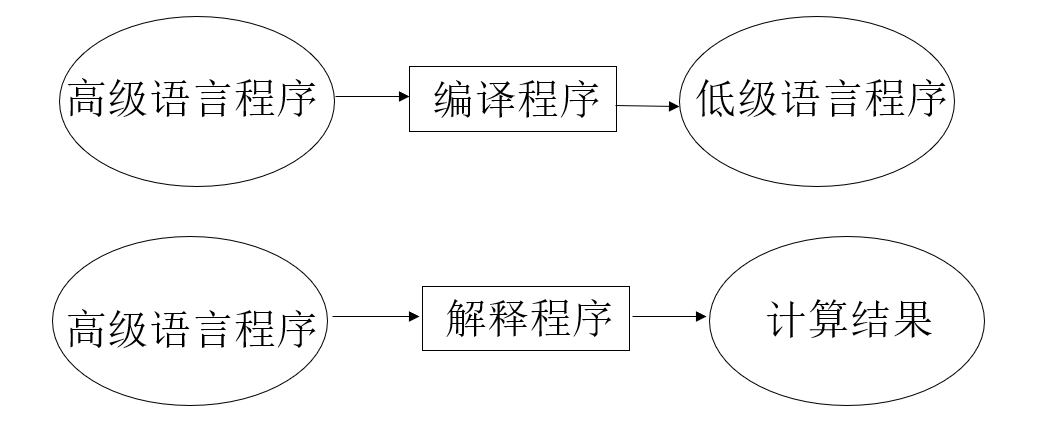
编译:整个程序全部翻译结束之后,程序才能开始运行;编译和运行是两个独立分开的阶段。
解释:不需要将分析和执行阶段分开,一边分析一边执行;更加适用于交互环境中。
编译和解释的比较
编译结果的执行效率比解释快很多
解释执行的空间开销大大超过编译结果的执行
Java C# 和 传统语言 C Pascal
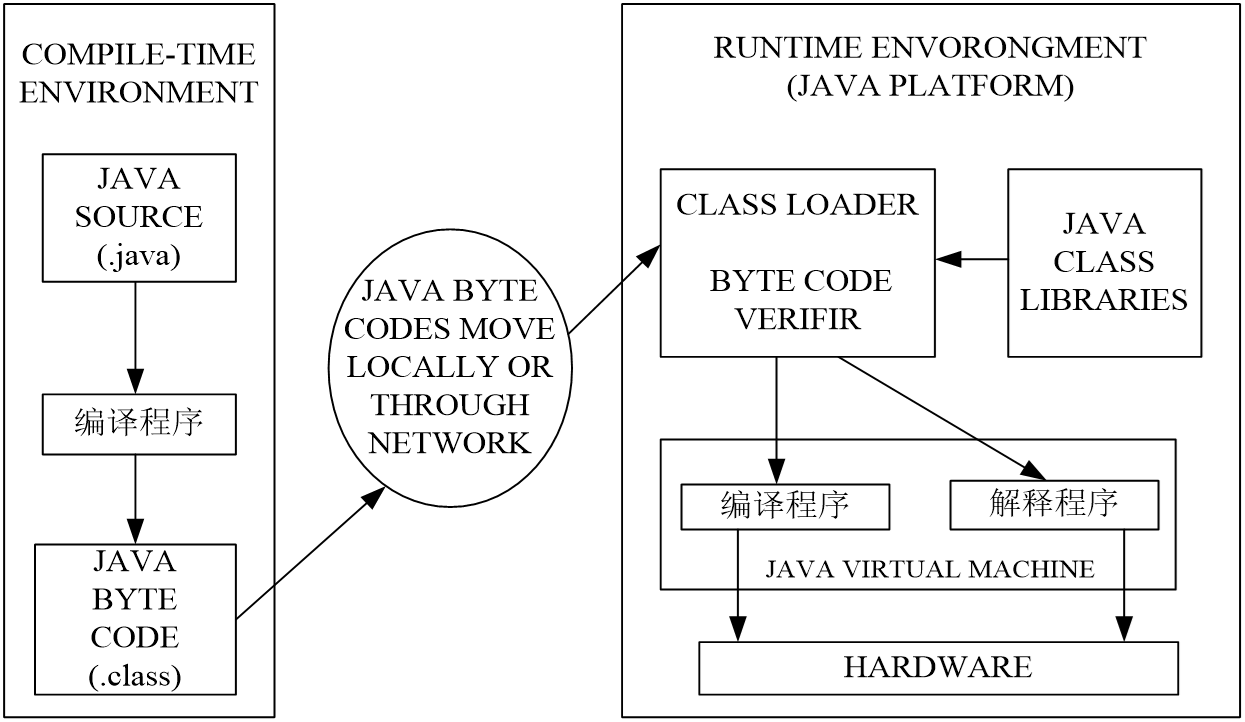
Java语言的处理环境既有编译程序,也有解释程序
java源程序经过JAVA编译程序编译后生成class可执行字节码文件(BYTECODE)
可执行字节码文件(BYTECODE)在java虚拟机(JVM)上经过解释程序一行行解释执行
可以说JAVA编译程序兼具编译型语言和解释型语言的特点
传统语言都是一次编译,没有生成中间代码
文法的概念
文法即是以有穷的集合刻画无穷的集合的一个工具。
文法类型与形式(0—3)

0型文法→短语文法
1型文法→上下文有关
2型文法→上下文无关
3型文法→正规文法
编程语言使用哪些文法
语法上使用的是上下文无关文法(2型)
标识符、数字等使用的都是正规文法(3型)
句型、句子
我不知道(ノ`Д)ノ
有害规则和多余规则
- 文法中不含有有害规则和多余规则
有害规则
形如U→U的产生式。会引起文法的二义性
多余规则
指文法中任何句子的推导都不会用到的规则
文法中某些非终结符(除了开始符)不在任何规则的右部出现,该非终结符称为不可到达。
文法中某些非终结符,由它不能推出终结符号串,该非终结符称为不可终止。
上下文无关文法及其语法树
最左(最右)推导:在推导的任何一步α=>β,其中α、β是句型,都是对α中的最左(右)非终结符进行替换,则称这种推导为最左(右)推导。
最右推导被称为规范推导,由规范推导所得的句型称为规范句型
短语:子树的所有叶子节点集合为一个短语,拥有多个子树就有多个短语(一个句型的语法树中任一子树叶结点所组成的符号串都是该句型的短语)
直接短语:子树中不再包含其他的子树,即A只能推导出b,而b不能再推出其他的式子,则b为此句型的直接短语
句柄:最左直接短语
文法的二义性与语言的二义性关系
如果一个文法存在某个句子对应两颗不同的语法树,则说这个文法是二义的。
二义性文法可能产生同一个语言。
如果产生上下文无关语言的每一个文法都是二义的,则说此语言是先天二义的。
优先关系概念

算符文法概念

子程序参数类型

机器指令

动态堆式分配

